
NotebookLM can now talk 👀 Updates from Google, Bandwidth, SoundHound, Hume and much more 🔥

Google NotebookLM can now explain complex topics out loud.

Top Updates 💪
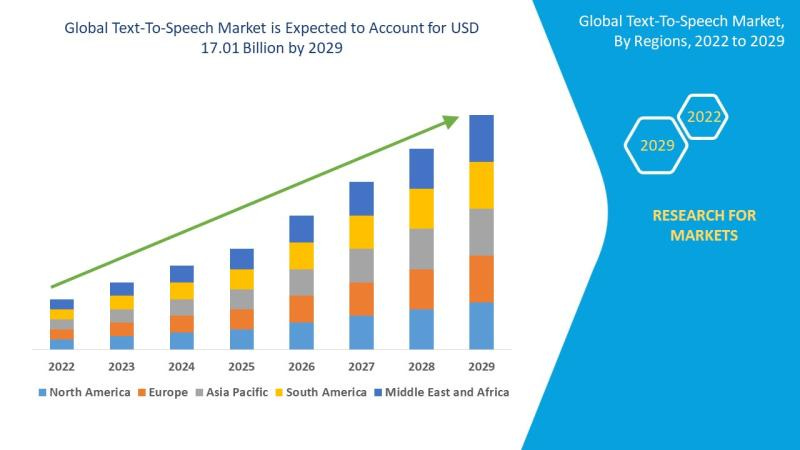
Text-to-speech market expected to reach $17B by 2029
Bandwidth unveils the largest BYOC ecosystem for enterprise solutions

Kanari AI and Kata AI form a strategic partnership to elevate conversational AI
AI-Media and Speechmatics announce strategic partnership
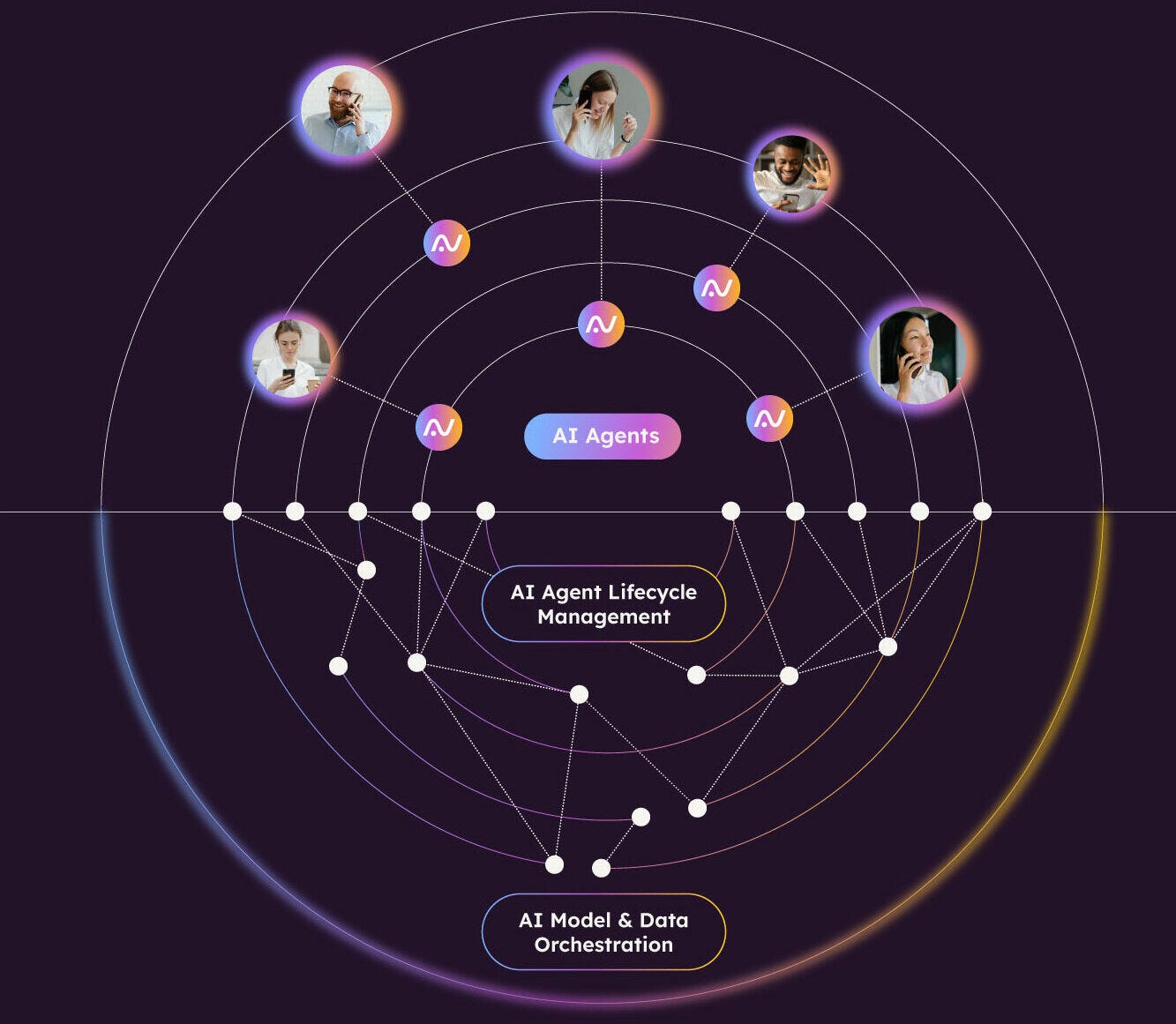
Parloa unveils its AI Agent lifecycle platform

Fish Audio unveils open-source TTS with multilingual support and voice cloning
Prodege launches new conversational AI feature
Mihup.Ai unveils advanced GenAI suite to boost Contact Centers performance
LLaMA-Omni: Open-source AI that’s giving Siri and Alexa a run for their money


Gemini’s voice mode is out now for free on Android
SoundHound AI acquires Amelia
Hume unveils EVI 2, its new voice-to-voice foundation model
Exotel unveils new local cloud and AI solutions for enhanced customer experience
Enterprise-focused AI translation platform Smartcat raises $43M in funding
Noteworthy 💪
CX AI startups: Blending innovation with tradition
Would you let an AI robot handle 90% of your meetings?
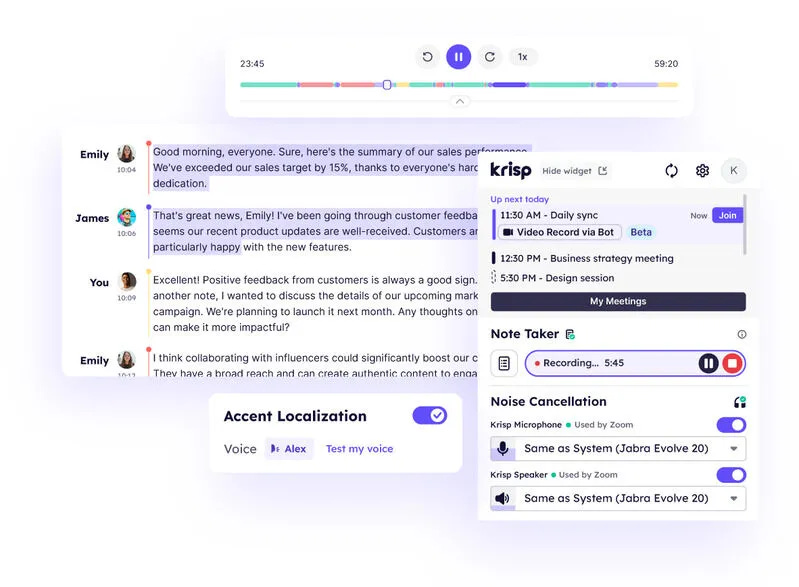
AI-powered meeting tools - Krisp offers transcription and noise cancellation

Jabra unveils its AI-powered speech enhancement solution for contact centers
Exploring AI ambient clinical voice and AI medical scribes
Phantom voices: Defend against voice cloning attacks
The sound of your voice may reveal that you have diabetes
DeFake tool protects voice recordings from cybercriminals
Altered AI review: Using AI for real-time voice morphing
Science and Demo Corner 😎
Integrating real-time speech translation API with Python
Amazon Transcribe: Transforming audio to text
Retrieval-augmented correction of named entity speech recognition errors
Apple proposes an algorithm to optimize byte-level STT and compare with UTF-8
Multi-speaker STT with multi-stage encoders and attention-weighted embedding
Refining synthesized speech using speaker information and phone masking
Textless unit-to-unit training for many-to-many multilingual speech-to-speech
Priority-encoder ensemble for speech recognition
ABR demonstrates the world's first single chip solution for full vocabulary STT
Whispered STT based on audio data augmentation and inverse filtering