

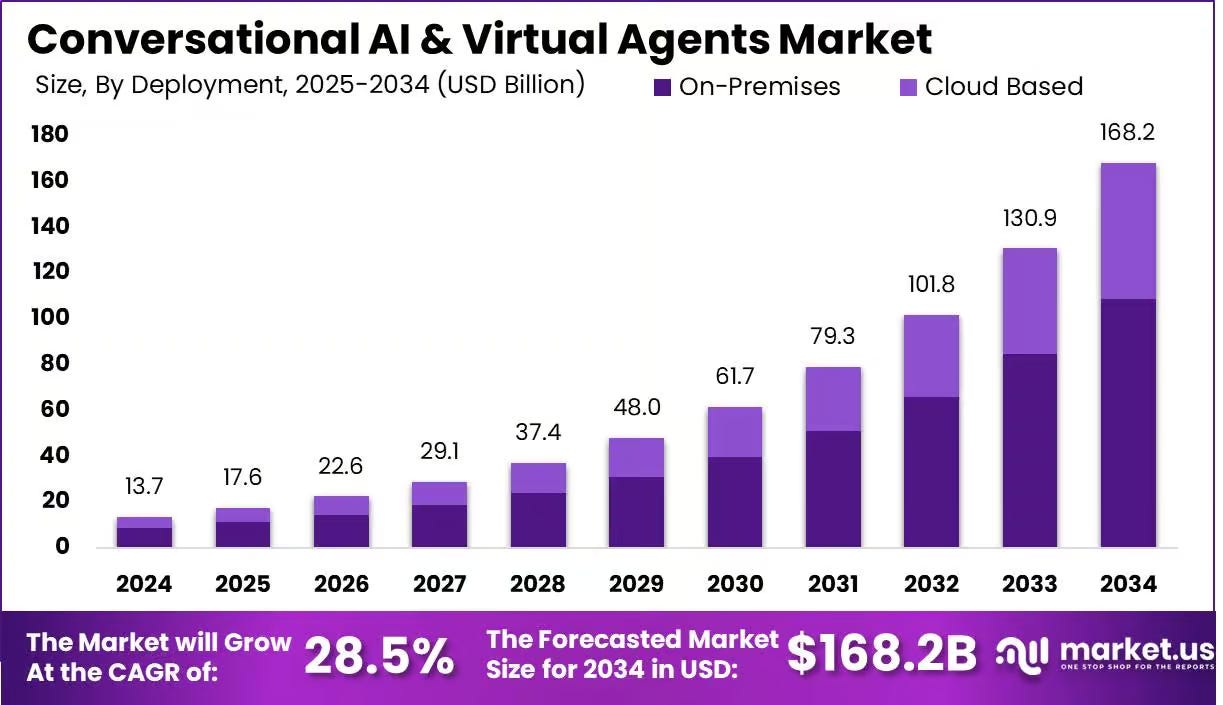
Conversational AI and Virtual Agents market size, share analysis reports (Market)
Top Updates 💪
Top contact center trends to watch in 2025 (Cmswire)
Microsoft adds GPT-4o mini audio models to Azure AI Services (Techzine)
Meta launches new program to improve speech and translation AI (Techcrunch)
Conversational Alexa being unveiled on Feb 26, as Siri waits until 2026 (9to5mac)
Bland: From pre-seed to Series B in under 10 months! (LinkedIn)
Wordtune wants to help convert AI content so that it sounds more like you (Cnet)
OneMeta & Utah Tech Week expand AI multilingual accessibility (Thewhig)
Humanizing AI Agents: Emotion detection and empathy in collaborative workflows (Forbes)
PlayAI's new Dialog model achieves 3:1 preference in human evals (Play)
How an anti-fraud startup fights deepfake fraud (Bankautomationnews)
Echo: AI for meeting summaries & transcription (Dynamicbusiness)
Enlisting Llama in India’s first open-source audio language model (Ai.meta)
Can reasoning LLMs transform Customer Experience? (Opusresearch)
Zaion secures EUR 11 million in round led by 115K (Thepaypers)
DT, Docomo invest in voice AI startup (Telecomtv)
AI could change the way the Super Bowl sounds (Sportico)
Voice AI Podcast 🎙️
In case you missed the latest episode of Voice AI Podcast…


Notable on X


Engineering Corner 😎
Alibaba outlines how LLMs can improve speech-to-text AI translation (Slator)
Meta Audiobox Aesthetics: Unified automatic audio quality assessment (Ai.meta)
Kokoro WebGPU: Real-time TTS 100% locally in the browser (News.ycombinator)
Voice-fn: Real-time Voice AI pipeline framework (Github)
Creating a TTS AI Agent in JavaScript using OpenAI API (Dev)
Hibiki: High-fidelity simultaneous speech-to-speech translation (Github)
After creating 2 million GPT tokens, this UNILAG student has built an AI text-to-speech model with Nigerian accent (Techpoint)
Auto-AVSR: Audio-visual speech recognition with automatic labels (Github)
New AI system SEAL makes speech recognition 15% more accurate with enhanced learning approach (Dev)
Llasa: Scaling train-time and inference-time compute for Llama-based speech synthesis (Arxiv)
JLMS25 and Jiao-Liao Mandarin ASR based on multi-dialect knowledge transfer (Mdpi)